Chronicle Queue - Kafka на минималках
Что, если нужна простая и высокопроизводительная очередь, но вы не хотите усложнять решение путём добавления полноценного брокера? Или нужно обеспечить распределённую обработку огромного потока событий с непредсказуемыми всплесками активности? Сегодня поговорим еще об одном классе решений – локальные очереди.
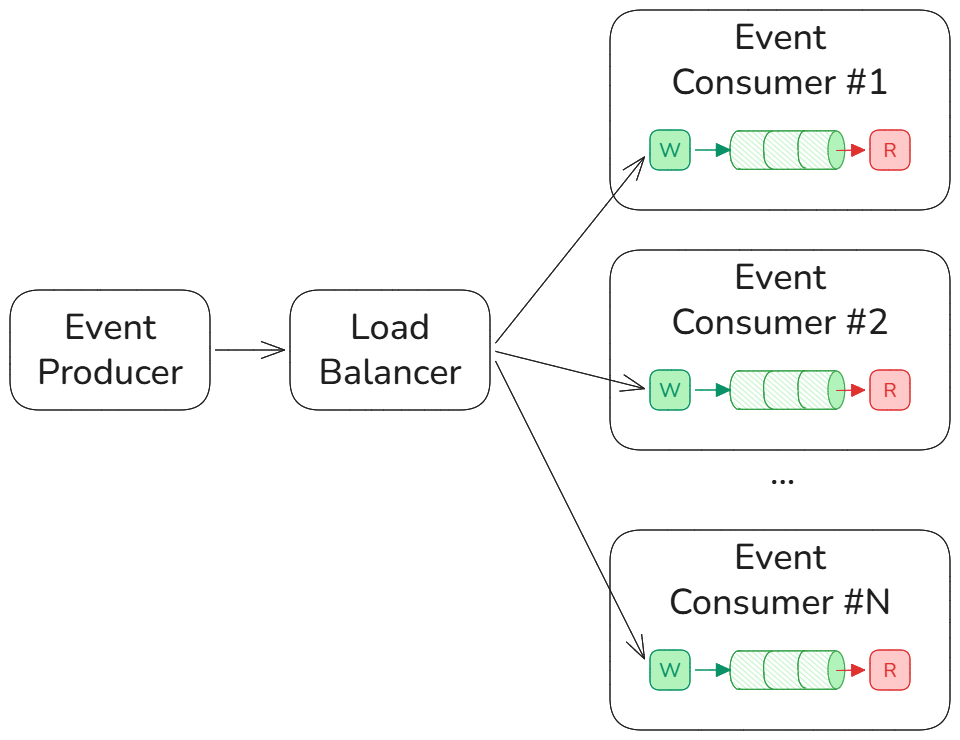
Контекст
Имеется связка Producer-Consumer, в которой Producer может генерировать события намного быстрей, чем Consumer успевает их обрабатывать. При этом Producer отправляет события синхронно, а Consumer не должен замедлять его работу, вынуждая ждать окончания обработки или требуя повторной отправки в случае ошибки.
Примеры:
- Высокочастотный источник, например, биржевые котировки – миллионы событий в секунду и/или случайные всплески активности. Нужно предоставить возможность быстрой записи событий, а их обработку делать в фоне.
- При обработке событий производится обращение к ресурсу с низкой доступностью, но нужно гарантировать успешность обработки. Например, гарантировать запись в БД или вызов сервиса, с которым возможна потеря сетевого соединения. Иначе говоря, когда нужно пережить недоступность внешнего компонента.
- Нужно обеспечить высокий уровень масштабируемости, параллелизма обработки и адаптируемости к нагрузкам. При этом порядок обработки событий в общем случае не важен. Например, система, подобная LeetCode, в которой агенты должны осуществлять проверку присылаемых решений во время проведения соревнований.
Проблема
Получив событие, Consumer сразу отвечает успехом, но добавляет задачу в очередь асинхронной обработки. С появлением очереди возникает целый комплекс проблем.
Где Consumer будет хранить необработанные события? Если в оперативной памяти, то можно быстро дойти до OOM/Killer. Если использовать брокер сообщений, то какой?
Если Kafka, то как адаптировать её под всплески активности и выбрать оптимальное количество партиций, fetch size, poll timeout и т.п.? А если в системе нет никакого брокера и его добавление крайне нежелательно или преждевременно? Например, не нужны все возможности Kafka, а её добавление выливается в огромные траты по сопровождению.
Решение
Суть решения:
- Consumer использует персистентную очередь, которую хранит в локальной файловой системе. Получив от Producer событие, Consumer сохраняет её в файл очереди – append-only-лог – и тут же отвечает успехом.
- Обработку событий из файла очереди Consumer выполняет в отдельном потоке или процессе. Если событие требует принципиально разной обработки, Consumer может запустить разные обработчики в разных потоках или в отдельных процессах.
Дополнительно нужно учесть:
- Каждый экземпляр Consumer должен иметь свой собственный файл очереди. Соответственно, в Docker нужно настроить Volumes; в Kubernetes – PV. Это позволит не потерять события при перезапуске Consumer.
- Желательно, чтобы Consumer реализовывал Graceful Shutdown, гарантируя обработку оставшихся сообщений в очереди до прекращения своей работы. Это позволит адаптировать количество обработчиков как в большую, так и в меньшую сторону.
- Для обеспечения микросекундных задержек, а также для возможности конкурентного доступа к файлу очереди, можно использовать Memory-mapped files – файлы, отображаемые на регион виртуального адресного пространства процесса. Это позволяет свести к минимуму затраты при работе с файлами, а также осуществлять межпроцессное взаимодействие через общий файл.
Шаблон реализуется самостоятельно, с помощью специальных библиотек, файловых или embedded-баз данных (RocksDB, SQLite, LiteDB и т.п.).
Для JVM/Java/Kotlin отличным решением может быть Chronicle Queue (при запуске в Java 17+ для JVM нужно указать дополнительные настройки).
Плюсы
- Концептуальная простота решения.
- Масштабируемость, адаптируемость, производительность.
- Высокий уровень параллелизма и распределённой обработки.
- Нет сетевых издержек на общение с брокером.
- Простота деплоя и сопровождения. Нет брокеров, которые нужно обслуживать.
Минусы
- Нет гарантий порядка обработки.
- Риск потери части событий при выходе из строя узла, на котором хранились файлы очередей. Снижать эти риски нужно самостоятельно.
- Нет партиционирования данных. Его нужно реализовывать самостоятельно, например, на уровне роутинга событий от Producer к Consumer.
- Если при усложнении системы вовремя не переключиться на какой-то брокер, можно перейти грань, когда “очень просто” станет “очень сложно”.
Понравилась статья?
Посмею напомнить, что у меня есть Telegram-канал Архитектоника в ИТ, где я публикую материал на похожие темы примерно раз в неделю. Подписчики меня мотивируют, но ещё больше мотивируют живые дискуссии, ведь именно в них рождается истина. Поэтому подписывайтесь на канал и будем оставаться на связи! ;-)
Статьи из той же категории: