Архитектура лечит причину
Архитектура должна лечить причину; в противном случае будете обречены бесконечно бороться с симптомами. Постараюсь объяснить эту аксиому на кейсах из практики.

Кейс 1: Аналог LeetCode
Контекст. Нужно реализовать систему проверки решений задач по программированию — аналог LeetCode. Пользователи присылают код решения, который компилируется и многократно исполняется на заданном наборе тестов. Результаты проверки сохраняются в истории решений пользователя, после чего он уведомляется о их готовности.
Было. Оркестратор координирует весь процесс проверки. Присылаемое решение сохраняется в истории, затем в очередь отправляется запрос на проведение проверки. Этот запрос получает оркестратор и начинает последовательно и синхронно исполнять все шаги проверки решения: компиляция кода; исполнение тестов; проверка результатов исполнения (сверка полученных ответов с правильными); сохранение результатов проверки в истории решений пользователя; отправка уведомления о готовности результатов. Поскольку для каждого языка программирования требуется своё окружение, а также с целью изоляции исполняемого кода, компиляция решений и исполнение тестов производится на отдельных узлах — песочницах. Соответственно, перед началом проверки оркестратор должен выбрать наименее загруженную песочницу.
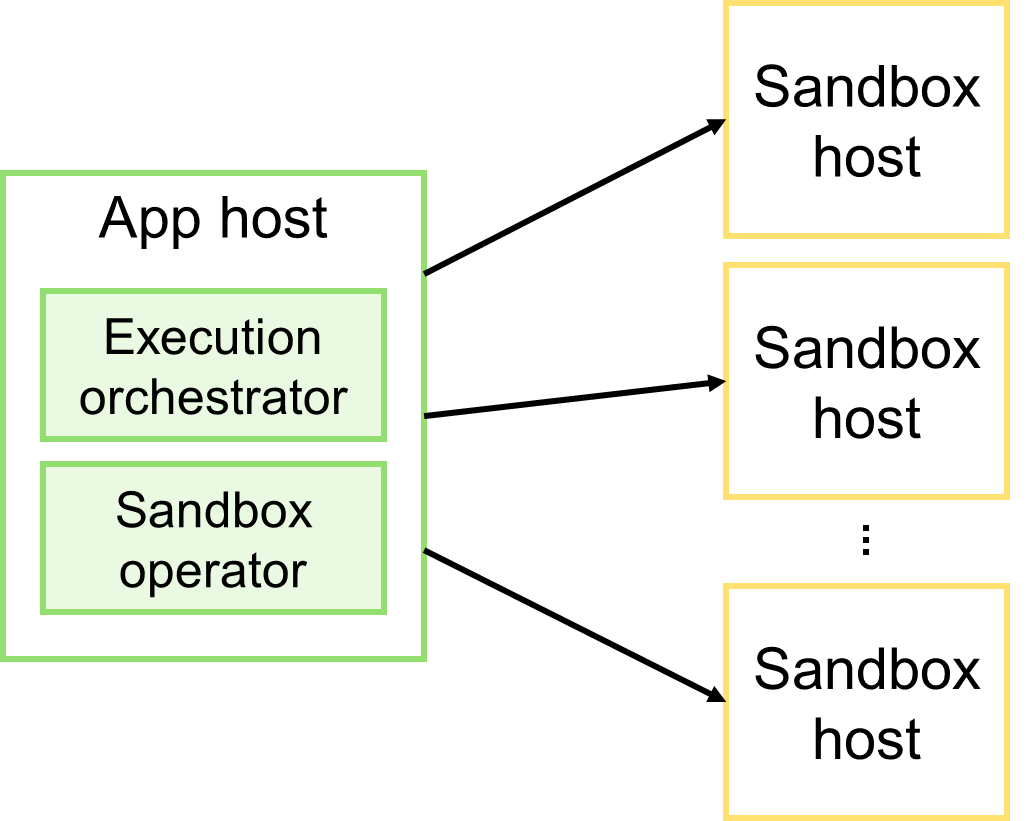
Проблемы. Оркестратор периодически перегружает песочницы, и они уходят то в CPU Throttling, то падают по OOM/Killer. Это влияет на качество получаемых результатов и увеличивает время проверки. Изначально простой и прямолинейный алгоритм оброс тонной инфраструктурного кода, который обрабатывает краевые сценарии с целью сформировать корректный результат проверки: балансировка нагрузки на песочницы, обработка всевозможных таймаутов, повторные попытки исполнения, самодиагностика и т.д. Никакие улучшения этого кода не решают проблему концептуально, лишь немного минимизируют вероятность негативных исходов. Из-за перегрузки песочниц вполне корректные решения получают некорректный вердикт. Например, CPU Limit, Wall Limit или даже OOM.

Лечение симптомов. Оптимизация кода, добавление эвристических алгоритмов оценки состояния песочниц, улучшение алгоритма балансировки нагрузки на песочницы. Несмотря на уйму потраченного времени, все улучшения лишь смягчали проблему, но не устраняли её полностью.
Причина проблем. Песочницы — разделяемый ресурс. Оркестратор синхронно выполняет шаги алгоритма и не может полноценно контролировать загруженность песочниц. Уровень параллелизма исполнения задач в каждой песочнице не детерминирован, что создаёт условия для неконтролируемого расхода ресурсов (CPU/RAM).
Лечение причины. Нагрузка на песочницы должна быть контролируемой. Пусть каждая песочница сама берёт решения на проверку по мере своего освобождения и текущей нагрузки, которую она может оценить гораздо эффективней, чем внешний оркестратор. Алгоритм проверки — прямолинеен и состоит всего из нескольких шагов: компиляция, исполнение тестов, проверка ответов, сохранение результатов, оповещение пользователя. Пусть каждый шаг будет этапом асинхронного конвейера. Таким образом, отказываемся от оркестрации и переходим к хореографии, выстраивая поток событий так, чтобы они соответствовали этапам конвейера проверки.
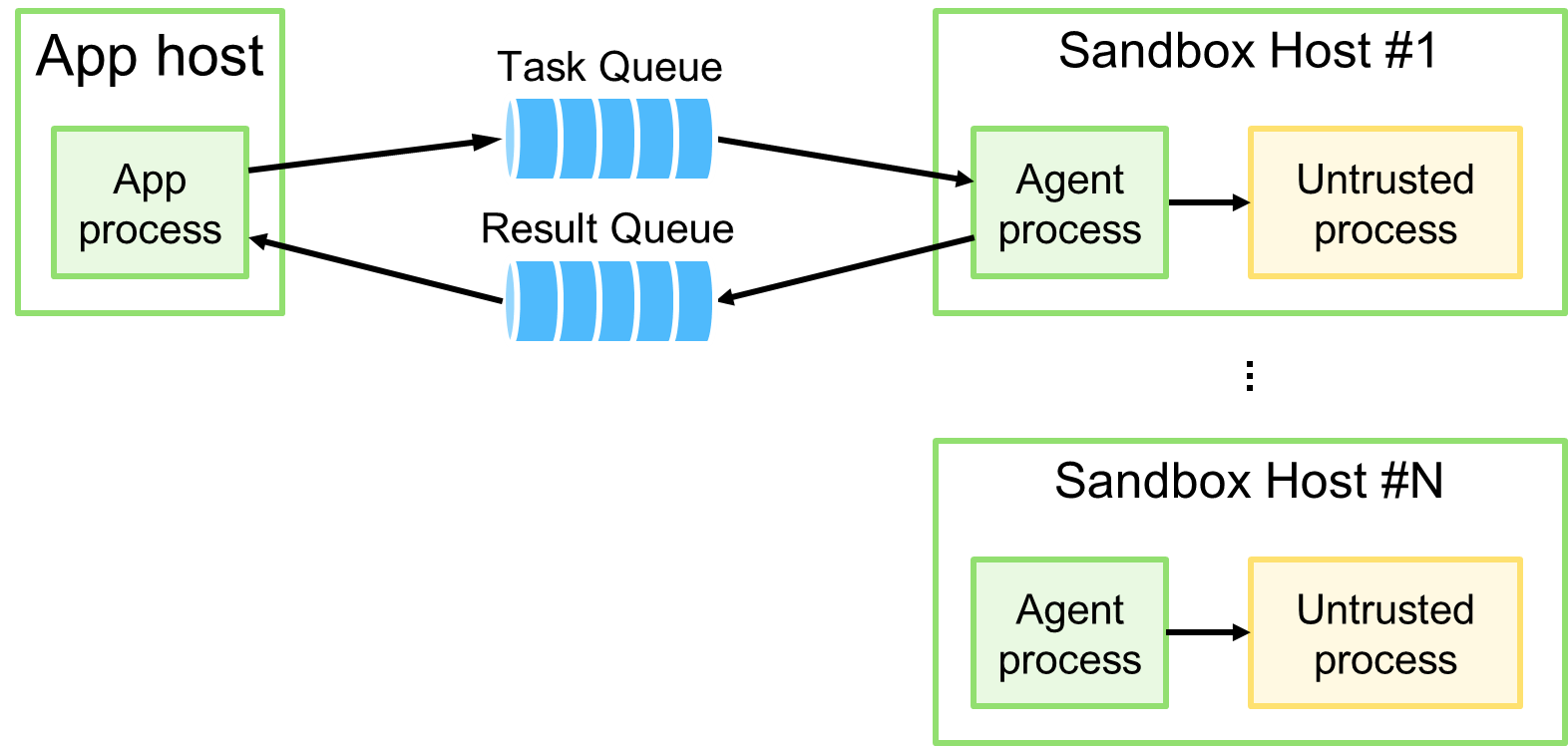
Что получили. Песочницы не перегружаются, и каждая работает в своём темпе. Больше нет CPU Throttling и OOM/Killer. Ушла тонна инфраструктурного кода и эвристик, осталась только бизнес-логика. Появилась возможность видеть заторы на каждом этапе конвейера и масштабировать его там, где это действительно нужно. По итогу улучшилось качество проверки, пропускная способность.
Как думаете, сколько ушло на оптимизацию кода и сколько на перестройку архитектуры? На все оптимизации ушло гораздо больше! И оптимизациям не было конца и края, эти работы были просто прекращены, т.к. только усложняли систему, не решая проблемы.
Если требуется бесшовный переход на новое решение, то самая сложная часть в реализации будет заключена в планировании этапов реструктуризации существующей системы. Решение не предполагает переписывание кода и основано лишь на инвертировании потока управления. Теперь не оркестратор заставляет песочницы работать, а сами песочницы берут работу по мере своей готовности; но при этом сам алгоритм работы каждого компонента остаётся прежним.
Кейс 2: Поиск медицинских документов
Контекст. В системе хранения медицинских документов необходимо реализовать их поиск, чтобы он отвечал заявленным требованиям по нагрузке, а нагрузка на поиск не оказывала влияние на остальную функциональность системы.
Было. Система имеет монолитную архитектуру и за многие годы своего существования обросла огромным количеством функционала, обращение к которому производится через синхронный SOAP API. Поиск документов является частью этого API. Пользователи отправляют поисковой запрос, сервис производит выборку документов из хранилища и выдаёт ответ.
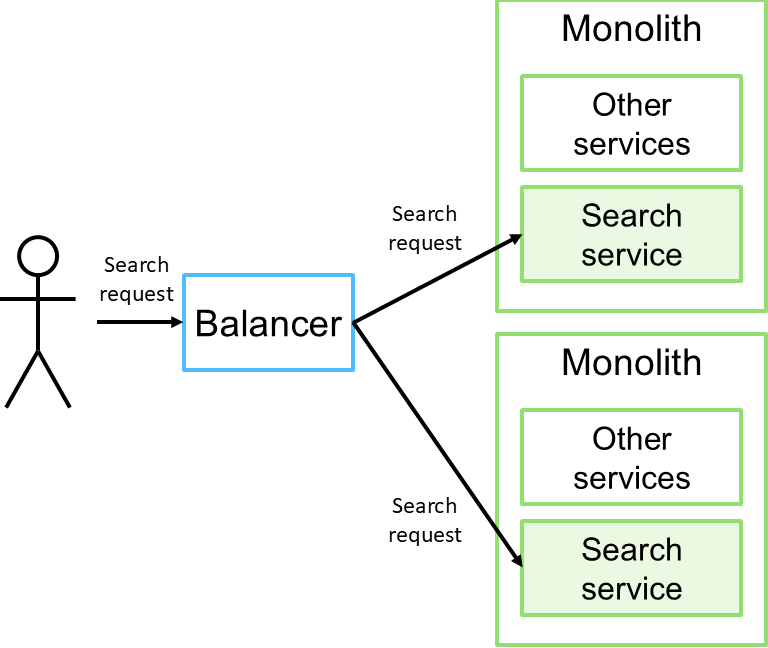
Проблемы. Обилие функционала монолита стало причиной его требовательности к ресурсам и окружению. Каждый экземпляр монолита нуждается в большом количестве вычислительных ресурсов, памяти и долгом времени запуска. Всё это сильно усложняет процессы деплоя, отката и масштабирования. Повышенная нагрузка на поиск без видимых причин провоцирует OOM, создавая операционные издержки и проблемы для остальной функциональности системы.
Лечение симптомов. Многократный анализ дампов памяти, проведение нагрузочного тестирования и последующая оптимизация кода, который потенциально мог стать причиной утечки. Несмотря на итеративное повторение этих упражнений, ситуация принципиально не улучшалась. После ударной нагрузки начиналось резкое снижение производительности, которое сопровождалось утечкой памяти с дальнейшим падением по OOM.
Причина проблем. Утечек памяти нет, но есть её неконтролируемый расход. Во-первых, слишком большое количество запросов создаёт слишком большой уровень конкуренции на уровне каждого экземпляра. Процесс пытается выполнить больше, чем может, и в итоге запускается “спираль смерти” из-за сборки мусора (GC). Во-вторых, обнаружилось неполное знание своих данных, из-за чего некоторые поисковые запросы становились причиной загрузки из хранилища в ОЗУ слишком большого объема данных, что в свою очередь также запускало “спираль смерти”.
Спираль смерти из-за сборки мусора — это состояние приложения, при котором оно не успевает справиться со сборкой накопившегося мусора (неиспользуемой памяти), а вновь поступающие запросы только усугубляют существующую ситуацию, приводя систему в ещё более плачевное состояние. Этот процесс может продолжаться достаточно долго, заканчивается падением по OOM, и сопряжён со снижением производительности обработки входящих запросов из-за активной работы сборщика.
Лечение причины. Поиск является достаточно обособленной функциональностью системы, и её нужно выделить в отдельный stateless-сервис, который можно развивать и масштабировать отдельно и независимо, возможно, даже на другом стеке. Такой сервис по сравнению с существующим монолитом будет легковесным и менее требовательным к ресурсам и окружению. Нагрузка на него не будет оказывать негативного эффекта на остальную часть системы, т.к. проблемы с сервисом не будут выходить за пределы его экземпляров.
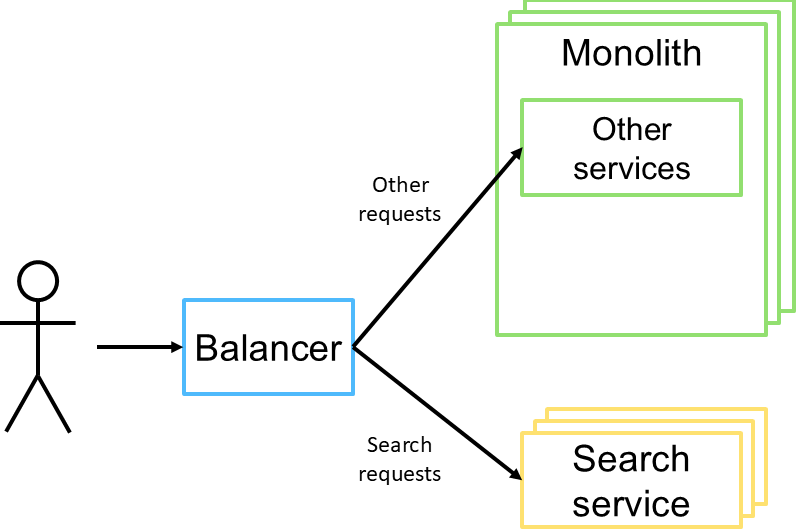
Что получили. Хорошо масштабируемое и поддерживаемое решение. Все усилия разработчиков направлены на улучшение производительности поиска.
В исходном решении предпринимаемая борьба с OOM — это задача, имеющая начало, но не имеющая конца. Можно было пытаться из последних сил масштабировать монолит, бесперспективно закидывая его железом. Можно было добавить серверный ограничитель частоты запросов (rate limiter), изменив существующий контракт API и спровоцировав переделки со стороны зависимых служб. И в любом случае причина проблемы никуда не уйдёт.
Лечение причины заключается в простой декомпозиции функционально обособленной части системы — выделении уже существующей stateless-функциональности в отдельно разворачиваемый модуль. По сравнению с бесконечным и безрезультатным профилированием, это простое решение с понятным и предсказуемым исходом, не требующее высокой когнитивной нагрузки. Сроки исполнения такой задачи можно оценить достаточно точно.
При этом нет никаких проблем с постепенным переходом на новое решение. Перенаправлением трафика к новому поисковому сервису может заниматься как входящий балансировщик (см. рисунок выше), так и само приложение (см. рисунок ниже).
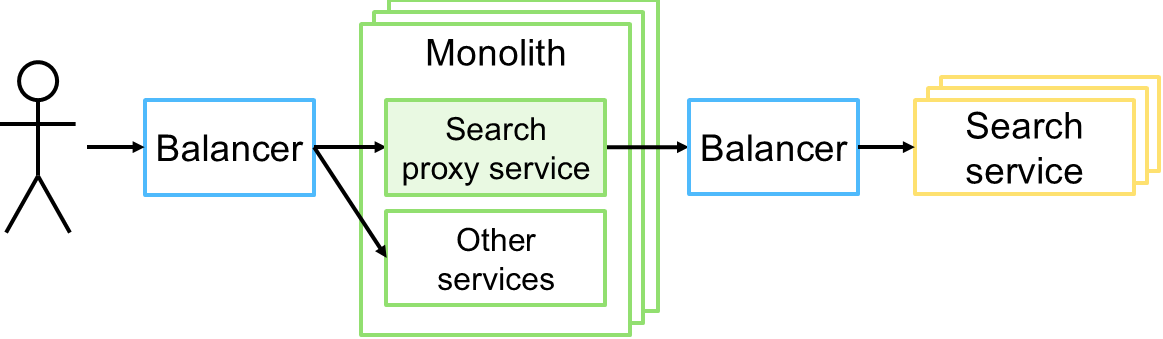
Кейс 3: Гетерогенное хранилище документов
Контекст. Необходимо реализовать систему хранения медицинских документов. Каждый документ состоит из метаданных и данных. Метаданные описывают назначение документа и его данные; данные хранят содержательную часть. Данные бывают структурированными (имеют известную схему представления информации, например, XML) и неструктурированными (бинарные данные). Сохранение, поиск и получение документов происходит с участием сложной, но достаточно прямолинейной бизнес-логики, включающей оповещение внешних систем об изменении данных. Метаданные хранятся отдельно от данных, т.к. структурированные и неструктурированные данные должны храниться в специализированных хранилищах. Необходимо обеспечить согласованное хранение документов, чтобы он сохранялся и извлекался целиком, метаданные всегда соответствовали данным и наоборот. Иначе говоря, должна быть логическая транзакция: документ сохраняется целиком или не сохраняется вообще.
Было. Для хранения документов используется целый зоопарк систем: Apache Cassandra для метаданных; специализированное хранилище структурированных медицинских данных; S3-совместимое хранилище для неструктурированных медицинских данных; PostgreSQL для прочих данных. Сохранение имеет ряд асинхронных этапов, включающих оповещение внешних систем об изменении данных. Запуск асинхронных этапов алгоритма выполняется через отправку сообщений в Apache Kafka.
Проблемы. Иногда наблюдается рассогласование данных: метаданные и данные не соответствуют друг другу; метаданные есть, данных нет; внешние системы не получили уведомление или получили его несколько раз и т.д. Всё это стало бременем операционной команды, но в некоторых случаях доходит до команды разработки. Из-за того, что метаданные в Cassandra хранятся по принципу “ключ-значение”, операционная команда не может выполнять произвольные аналитические SQL-запросы, чтобы проанализировать состояние документов. Дополнительно административно инициирована активность по импортозамещению используемых программных компонентов, что создало риск дальнейшего использования Cassandra.
Лечение симптомов. Добавление инфраструктурного кода, который обрабатывает краевые сценарии и выполняет различную компенсационную логику, если это возможно. Например, если не удалось сохранить данные документа, то откатить сохранение метаданных; делать повторные попытки отправки уведомлений в случае неудачи и т.д. Всё это усложняет код, смягчая, но решая проблему.
Причина проблем. Учитывая гетерогенное хранение документов, изоляции в такой системе никогда не было, а её реализация крайне затруднительна, поэтому всё, о чём имеет смысл говорить, это итоговая согласованность (eventual consistency). Таким образом, основная причина проблемы заключена в отсутствии координирующего механизма, который бы предоставлял гарантии порядка и успешности выполнения всех этапов сохранения документа.
Лечение причины. Использовать готовый координатор/оркестратор бизнес-транзакций, например, Temporal, т.к. самостоятельная реализация саг (sagas) и outbox/inbox-шаблона — это слишком дорогое удовольствие. Учитывая дополнительные обстоятельства в виде импортозамещения, стоит всерьёз присмотреться к YDB, включая YDB Topics. По многим критериям метаданные медицинских документов идеально подходят для хранения в YDB, которая среди прочего имеет поддержку ACID-транзакций между таблицами и топиками, а также SQL, необходимый для операционной команды. Прямолинейный алгоритм сохранения медицинского документа без труда и опасения может быть реализован с использованием ACID-гарантий YDB Topics, что в свою очередь не потребует использования сторонних решений координации вроде Temporal, саг или outbox/inbox-шаблона.
Что получили. Настоящие гарантии eventual consistency. Этапы сохранения документа содержат минимум инфраструктурного кода и неестественных эвристик. Существенно снижена нагрузка на операционную команду, т.к. больше нет проблем с согласованностью, а зоопарк систем заменён единой платформой данных — YDB/Topics заменяет то, для чего ранее использовались Cassandra, PostgreSQL и Kafka.
Внедрение оркестратора бизнес-транзакций — это консервативный минимум, который можно сделать достаточно быстро, учитывая, что Temporal для хранения состояния бизнес-транзакции может использовать как Cassandra, так и PostgreSQL, которые уже есть в стеке решения.
Рекомендуемое решение — переход на YDB/Topics — это стратегически верное решение для данной системы. Основная и самая сложная задача на этом пути — это миграция данных из Cassandra и PostgreSQL в YDB. Замена Kafka на YDB Topics не потребует особых усилий, т.к. YDB Topics поддерживает Kafka API.
Ни одно из решений не предполагает переписывания существующего кода. Основные изменения коснутся только инфраструктурного кода. Между тем оба решения — это задачи с понятным исходом, этапы и сроки реализации которых можно оценить достаточно точно.
Послесловие
Если архитектура не решает корень проблемы, пересматривайте её! Цепляясь за неудачное архитектурное решение, вы провоцируете лишь бесконтрольное усложнение системы. В итоге у разработчиков, как у самураев, не будет цели, только путь; каждый следующий шаг на этом пути будет тяжелей предыдущего, а повернуть назад однажды может быть очень непросто. Не становитесь такими самураями, своевременно производите реструктуризацию решения и не забывайте о неизбежности эволюции программных систем.
И еще одно важное дополнение. Если кто-то озадачился вопросом, почему предлагаемые выше решения не были очевидны изначально. Во-первых, следует вспомнить закон Гола: сложные рабочие системы получаются только из простых и рабочих. Во-вторых, иногда осознание причины требует глубокого погружения в детали проекта и должной широты взгляда на все процессы системы.
Понравилась статья?
Посмею напомнить, что у меня есть Telegram-канал Архитектоника в ИТ, где я публикую материал на похожие темы примерно раз в неделю. Подписчики меня мотивируют, но ещё больше мотивируют живые дискуссии, ведь именно в них рождается истина. Поэтому подписывайтесь на канал и будем оставаться на связи! ;-)
Статьи из той же категории: