Первичный анализ задачи поиска медицинских документов
Сегодня предлагаю рассмотреть вполне конкретную задачу из реального проекта. Думаю, что подобный кейс достаточно интересен и его можно рассматривать для прокачки своих навыков по System Design.

Сразу скажу, что мы ещё не полностью решили описанную ниже задачу. Представленное решение — лишь один из возможных вариантов, черновик, который ещё не проверен на практике. Однако, выполнив достаточно подробный анализ, я решил поделиться им с вами, а не оставлять пылиться результаты проделанной работы у себя в столе. В статье постарался адаптировать материал, чтобы он был понятен широкому кругу читателей и не требовал глубокого погружения в предметную область. Надеюсь, у меня получилось, и желаю вам приятного чтения.
Задача
Необходимо реализовать быстрый поиск по метаданным медицинских документов.
Грубо говоря, метаданные описывают содержимое документов с помощью набора атрибутов, которые можно поделить на три категории:
- общие атрибуты;
- атрибуты, характерные для типа документа;
- атрибуты, описывающие связи с другими документами.
Небольшая часть атрибутов присутствует у всех документов, например, “ID пациента”, “дата создания”, “тип документа”, “состояние” и т.д. Однако документы бывают разных типов, соответственно, атрибутивный состав метаданных разных типов документов — разный. Например, состав атрибутов для “Осмотра терапевта” отличается от “Осмотра кардиолога”. Описание семантических связей между документами также является частью метаописания. Например, “Направление на анализы” может содержать ссылки на результаты (и наоборот).
Типы данных атрибутов — скаляры (в основном целые числа разной разрядности, строки) и списки скаляров. Атрибутивный состав может меняться динамически, во время работы системы, без необходимости её повторного развертывания.
Поиск документов сводится к их фильтрации по атрибутам. Условие фильтрации может быть сложным логическим выражением — произвольной комбинацией операторов OR/AND/NOT. Поиск по связанным документам не производится, но может производиться проверка наличия связей.
Поисковые запросы можно поделить на две категории:
- Поиск по пациенту — это поиск внутри электронной медицинской карты пациента, фильтрация документов определенного пациента — подавляющая часть запросов. Например: “найти все обращения пациента к кардиологу”.
- Популяционный поиск — это фильтрация документов без указания пациента — малая часть запросов. Например, “найти документы, подписанные выбранным врачом”; “найти все больничные листы, выданные указанной поликлиникой за прошедший месяц”.
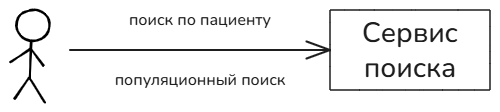
Важно, что подавляющая часть поисковых запросов идёт без указания периода создания документов. Иначе говоря, практически никогда не бывает запросов вида: “найди документы, созданные за последний год”, “за последний месяц” и т.п.
По умолчанию результат поиска должен быть отсортирован по дате создания документов в обратном хронологическом порядке (от новых документов к старым).
Документы могут изменяться несколько раз подряд. Нужно, чтобы поиск возвращал релевантные данные, игнорируя старые версии документов.
В идеале решение должно предполагать возможность постраничной выборки.
Уточнение требований
Разрабатываемая медицинская система уже имеет функцию поиска. Она реализована на базе SQL-хранилища, выполняет все функциональные требования, но работает крайне медленно. Поисковый запрос трансформируется в SQL-запрос, который представляет собой оператор SELECT с множественными INNER JOIN и операциями фильтрации, которые соответствуют переданному запросу.
Существующее решение таково, что поиск осуществляется по операционному хранилищу, следовательно, документ доступен для поиска сразу после сохранения. Возможно, что некоторые пользователи сервиса рассчитывают на это поведение, поэтому целевое решение должно стремиться к минимальной задержке между моментом, когда данные были изменены и когда они стали доступны для поиска.
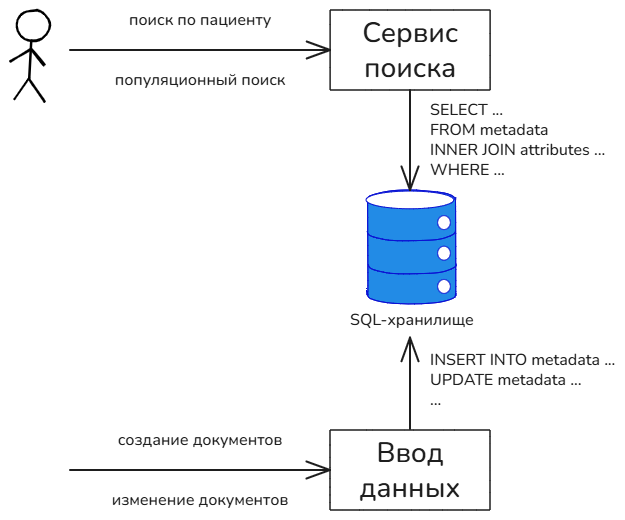
Система существует долгие годы, и так сложилось, что некоторые смежные продукты, обнаружив чрезмерную гибкость API сервиса поиска, стали отправлять популяционные запросы. Однако в общем случае популяционный поиск не является задачей медицинской системы, т.к. для её эффективного решения нужно строить витрины данных, а вид витрин сильно зависит от специфических потребностей отдельно взятого продукта. Следовательно, смежные продукты должны самостоятельно организовывать необходимые им витрины данных, а медицинская система, в свою очередь, обязана лишь предоставлять механизм, необходимый для организации таких пользовательских витрин. Например, система может публиковать асинхронные уведомления об изменениях документов.
Таким образом, принято стратегическое архитектурное решение, что смежные продукты будут постепенно отказываться от популяционных запросов, организуя собственные витрины данных. Соответственно, нужно идентифицировать всех таких пользователей, уведомить их о необходимости доработок и обговорить сроки реализации.
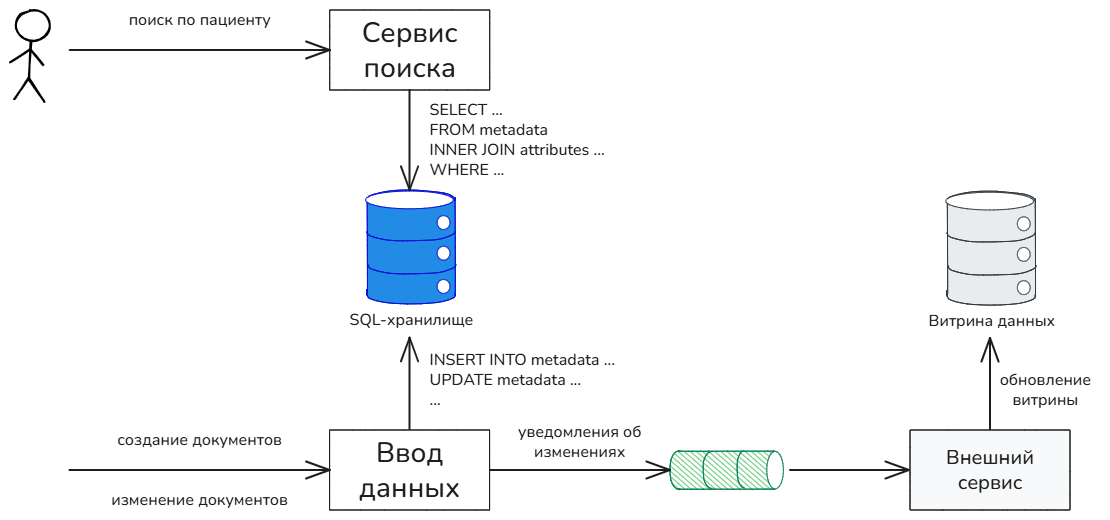
Между тем, популяционный поиск существует, поэтому искомое решение должно учитывать этот сценарий и обеспечивать его должную производительность. Даже самые оптимистичные прогнозы говорят о том, что отказ от популяционных запросов может занять несколько лет. Это большой срок, чтобы игнорировать необходимость реализации данной функциональности.
Нефункциональные требования
Текущая база данных такова:
- Количество пациентов:
25 000 000 - Количество документов:
5 000 000 000 - Количество общих атрибутов: до
20 - Количество дополнительных атрибутов: до
50(чаще до5) - Количество связей: до
100(чаще до2)
Динамика прироста базы данных:
- Прирост населения в год:
120 000 - Прирост документов в день:
5 000 000 - Количество лет для прогноза:
10
Показатели производительности:
- Показатель нагрузки:
1000RPS. - Время поиска по пациенту: ≤
200ms (P99). - Время популяционного поиска: ≤
1000ms (P99). - Лимит на количество строк в результате поиска:
2000 - Задержка сохранил/нашёл: ≤
1000ms
Известные проблемы и ограничения
Для понимания последующих выводов необходимо добавить расширенный контекст: что уже пробовали, с какими проблемами и ограничениями сталкивались. Во многом благодаря этому и появилась потребность в решении рассматриваемой задачи.
Реляционные базы данных
Большинство запросов имеет фильтр по идентификатору пациента, а документов у одного пациента не так много. Если посмотреть на исходные данные, в среднем 200 документов на каждого пациента. С такими запросами может справиться и реляционная база данных, достаточно добавить индекс на идентификатор пациента, и он существенно ограничит размер выборки. Однако есть несколько обстоятельств, почему такой вариант не рассматривается.
-
С ростом хранилища понадобится партиционирование и шардирование. С этим могли бы справиться распределённые SQL-базы, но заказчик установил ограничение, и можно использовать только PostgreSQL, а с его масштабированием есть вполне определённые трудности.
-
Проблема с множественными
INNER JOINникуда не уходит. Как показала практика эксплуатации текущего решения на базе SQL-хранилища, это заметно снижает производительность. Делать денормализацию (и “широкие таблицы”) под каждый тип документа не вариант, т.к. типов очень много и они появляются динамически. Гораздо проще хранить вариативный состав атрибутов в JSON-колонке. -
Для решения проблемы с популяционными запросами придётся делать срезы данных — отдельные вспомогательные таблицы, которые будут хранить данные в удобном для чтения виде. Скорей всего, само приложение будет ответственно за создание и актуализацию таких срезов.
Поисковые базы данных
Решать задачу поиска без рассмотрения такой базы, как Elasticsearch, было бы глупо. На самом деле новое решение, которое разрабатывается в настоящий момент, как раз основано на использовании Elasticsearch. Между тем с его использованием в данной задаче есть проблемы.
-
В идеале индексируемые данные должны быть append-only: добавляться и никогда не изменяться. Как только появляется необходимость обновления записи, производительность существенно падает, вызывая крайне негативный отклик на уровне I/O. Между тем, медицинские документы обновляются. И если в индекс производить только добавление, то в нём появляются старые версии документов, которые нужно фильтровать или удалять.
-
Сложные логические выражения в фильтре являются настоящим испытанием, особенно при фильтрации сложных структур данных, которые появляются из-за вариативного состава атрибутов. Тут было испробовано очень много вариантов мапинга и способов построения запросов, но идеального до сих пор не нашли.
-
Для решения проблемы с популяционными запросами придётся делать срезы данных. На данный момент сделано несколько таких “ускорителей” и, к сожалению, не только на уровне Elasticsearch. С одной стороны, они работают, с другой, это снижает общую доступность сервиса поиска, ведь он становится зависим не только от Elasticsearch.
-
Дороговизна решения на базе Elasticsearch — это отдельный пункт. Медицинские данные — это не каталог товаров — сегодня одни, завтра другие. Это данные, которые нужно хранить десятилетиями. Даже текущие потребности в ресурсах, к сожалению, не внушают оптимизма в перспективности использования этой базы. Даже существующее решение на базе SQL-хранилища требует меньших ресурсов, работая не менее производительно.
Анализ условий
Сделаем декомпозицию и анализ исходных условий. Большая часть анализа сконцентрирована на проработке требований к хранилищу данных, организации хранения и методам поиска.
Прежде всего нужно выделить основные архитектурные свойства сервиса поиска:
- Доступность. Поиск медицинских данных — это ключевая часть медицинской системы. Если она будет недоступна, то многие сценарии работы будут парализованы. Хранилище, которое будет выбрано для организации поискового индекса, должно обладать хорошей доступностью.
- Производительность. Как следует из условий, производительность поиска важна, но не критична. Тем не менее, рассматриваемая задача решается в первую очередь из-за проблем с производительностью. Особое внимание следует уделить быстродействию выполнения запросов.
- Масштабируемость и адаптивность. База данных активно растёт, количество пользователей растёт, уровень цифровизации увеличивается. Необходимо, чтобы система могла адаптироваться ко всё растущим потребностям. База данных и используемые подходы к хранению должны соответствовать данному требованию.
Далее часто будет использоваться термин поисковый индекс. Будем считать, что это структуры данных поискового хранилища, которые позволяют осуществлять быстрый поиск. Поисковый индекс может быть реализован по-разному — это может быть одна или несколько таблиц в базе данных, бинарный индекс, префиксный индекс и т.п. Главная его задача — ускорение поиска.
Общие требования
Решаемая задача — это не поиск, а фильтрация данных. Поиск — достаточно многозначный термин, который предполагает некоторую нечёткость в запросе. Например, “поиск по ключевым словам”, “поиск по фразе”, “поиск по смыслу”. В текущем контексте мы решаем задачу фильтрации данных, которая не допускает вариативности в толковании условий запроса или нечёткости результатов его выполнения.
Например, если среди всех документов выбранного пациента есть только 2 осмотра терапевта, а в поисковом запросе указано, что нужно вернуть документы с типом “Осмотр терапевта”, то результатом выполнения такого запроса ожидаемо должен быть набор из этих 2 документов. Соответственно, результат не предполагает, что в ответе вернутся все документы, в которых встречается фраза “Осмотр терапевта” или что-то в этом роде.
Таким образом, решение не подразумевает нечёткий поиск, например, полнотекстовый поиск, поиск похожих значений и т.п. Напротив, нужно решить задачу чёткого поиска, фильтрации данных. Следовательно, выбираемые инструменты должны в первую очередь эффективно решать задачу фильтрации данных.
Особенности запроса
По условию фильтр — сложное логическое выражение с произвольной комбинацией операторов OR/AND/NOT. Подобные запросы типичны для OLAP-хранилищ и совершенно нетипичны, например, для OLTP и полнотекстовых индексов. Делать аналитические выборки по OLTP, в которой данные хорошо нормализованы, ещё то удовольствие.
Возможная вариативность атрибутов в условии фильтрации полностью исключает возможность использования реляционных СУБД, т.к. ни одна реляционная база не выдержит создания огромного количества индексов на каждый искомый атрибут. Без индексов поиск будет работать, но медленно, неэффективно, с большой утилизацией CPU и I/O. Именно этот результат демонстрирует существующее решение на базе SQL-хранилища.
С другой стороны, вариативность атрибутов в условии фильтрации — характерная нагрузка для колоночных баз данных, например, ClickHouse или Apache Druid. Именно поэтому некоторые OLAP-хранилища — это колоночные базы данных.
Например, в ClickHouse атрибуты (колонки) хранятся в отдельных файлах данных, что положительно сказывается на эффективности выполнения запросов. Если в условии фильтрации фигурируют только 2 атрибута, то и считываться с диска будут данные только из 2 файлов. Это значительно эффективней, т.к. считываются именно те данные, которые нужны для поиска. Такой подход существенно отличает колоночные базы от строковых, в которых данные хранятся построчно, и при вычитывании строк вычитывается множество ненужных данных: все колонки строки, а также соседние строки, ведь файлы данных читаются с диска блоками фиксированных размеров. Подобное поведение колоночных баз существенно снижает нагрузку на I/O.
Дополнительно, колоночное хранение позволяет существенно сжимать данные (в среднем до 10-20 раз, в зависимости от вариативности значений в атрибутах), следовательно, экономить на хранении. Сжатие данных предполагает не только компрессию, но и удаление повторяющихся значений. Благодаря этому размеры колоночных файлов становятся незначительными, что приводит к кратному ускорению поиска, снижая нагрузку на I/O.
Наконец, в колоночных базах для каждой колонки может строиться вероятностный индекс (например, Bloom- или HLL-фильтр). Этот индекс формируется на основе вставляемых данных. Используя его, можно практически моментально узнать, есть ли в файле искомое значение. Это избавляет от бессмысленного сканирования файлов данных, снижая нагрузку на I/O.
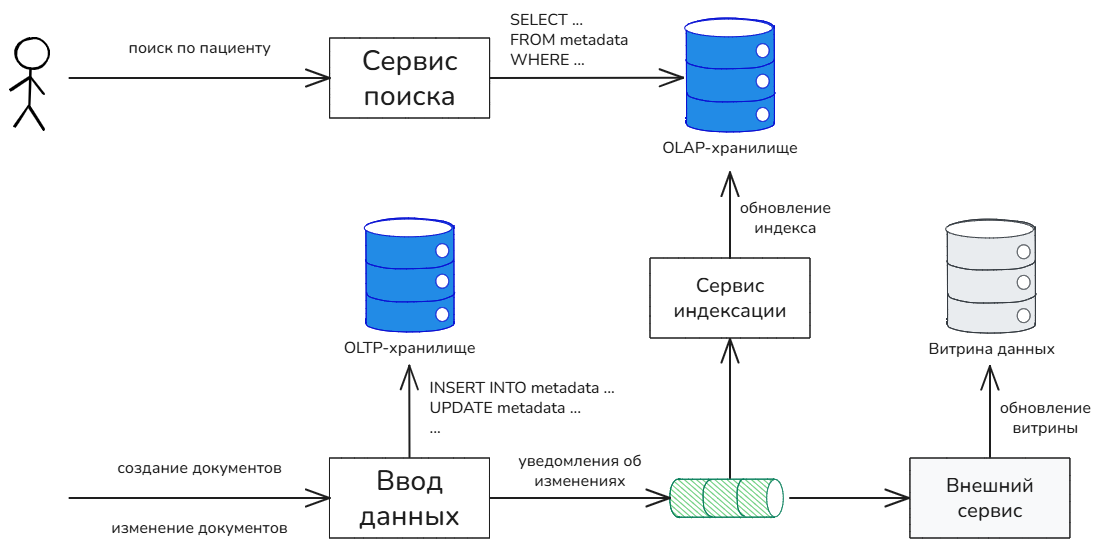
Особенности хранения
По условию задачи большинство, если не все, поисковые запросы идут без указания периода создания документов, что могло бы ограничивать объем обрабатываемых данных. Без подобной фильтрации поиск неявно предполагает сканирование всей базы данных за все периоды. В такой постановке время поиска будет расти вместе с ростом базы. Естественно, такое решение недопустимо, время поиска не должно зависеть от размера базы, и нужно найти подход, который ограничит выборку данных даже при отсутствии в пользовательском запросе фильтра по дате создания документов.
Для выполнения поставленной задачи напрашивается какое-то разбиение всего множества данных на группы фиксированных размеров (партиции), но так, чтобы при выполнении запросов можно было выбирать не все, а только определённые партиции. Такой подход, как минимум, обеспечит независимость времени поиска от размера базы и, вероятно, благоприятно скажется на скорости поиска. Однако, чтобы понять, как именно сделать партиционирование данных, нужно рассмотреть и принять к сведению нижеследующие факты.
- Поток сохраняемых документов условно бесконечный. Количество пациентов ограничено, но есть риск неравномерного распределения данных по разным группам пациентов.
- Результат поиска должен быть отсортирован по дате создания документов. Разумно, если документы сразу будут храниться в сортированном виде, чтобы не сортировать данные при каждой выборке.
По совокупности напрашивается единственно верный вывод: документы в основной таблице поискового хранилища должны храниться с партиционированием по времени создания и с предварительной сортировкой по времени создания (в обратном хронологическом порядке — от новых документов к старым, как требуется по условию).
Подобный подход обеспечит равномерное распределение данных по всем партициям, что неминуемо ограничит и усреднит максимальное время фильтрации по каждой партиции. Более того, такое распределение может производиться в автоматическом режиме, без необходимости ручной настройки диапазонов (например, при партиционировании по пациентам возник бы вопрос о количестве партиций). Гранулярность партиционирования (по годам, месяцам, неделям и т.п.) концептуально не важна, но будет рассчитана позже.
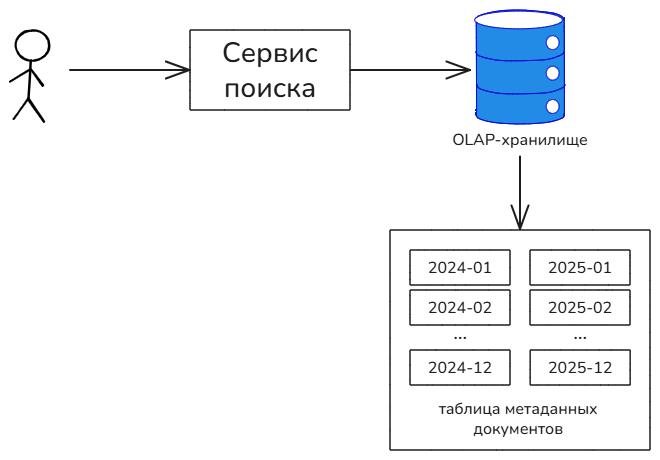
Партиционирование по дате создания в том числе позволяет решить вопрос с автоматическим ограничением объема обрабатываемых данных. Для каждого пациента нужно хранить сведения, за какие периоды по нему есть документы. Например, в виде вспомогательной таблицы “пациент — список дат” или “пациент — минимальная дата — максимальная дата”. Окончательный вид этой таблицы следует определить на этапе реализации. Вспомогательную таблицу можно заполнять во время записи в поисковый индекс, а затем использовать во время поиска в качестве “ускорителя”. Такой подход можно организовать без дополнительного программирования, путём создания материализованного представления (materialized view), которое будет строиться на базе основной таблицы поискового индекса. Сервис поиска будет писать только в основную таблицу, а база данных будет автоматически формировать и обеспечивать консистентное представление вспомогательной таблицы. Материализованные представления поддерживают все известные OLAP-хранилища. В крайнем случае вспомогательную таблицу можно формировать и вручную, в коде приложения.
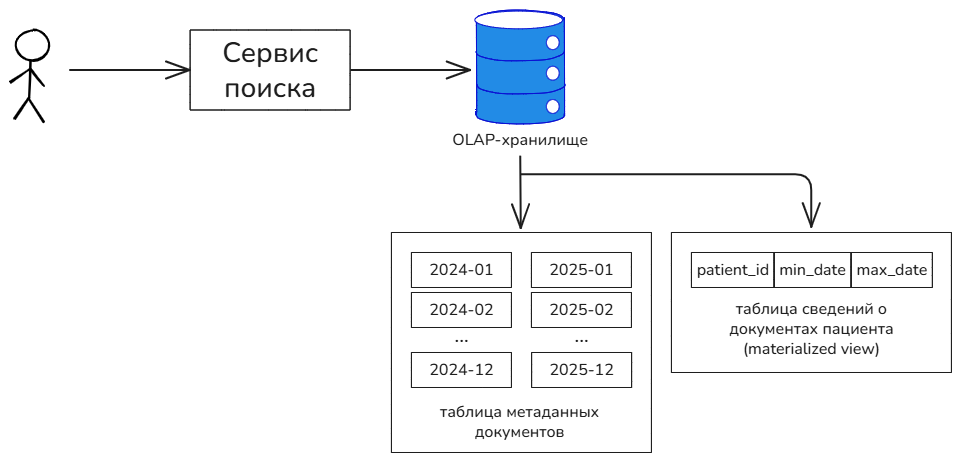
Актуализация поискового индекса
Документы могут изменяться, следовательно, поисковый индекс может устаревать, т.е. хранить старые версии документов. В существующем решении на базе SQL-хранилища такого не происходит, т.к. поиск осуществляется по операционным данным (данные сохраняются в те же таблицы, по которым осуществляется поиск). Очевидно, что новое решение должно, во-первых, минимизировать время индексации — новые данные должны появляться в индексе как можно быстрей; во-вторых, удалять из индекса старые версии документов, чтобы вероятность их появления в результатах поиска была минимальна, и они не занимали место на диске.
Для любой БД удаление — это тяжёлая операция. Это вполне объяснимо: хранилища данных проектируются для хранения данных, а не для их удаления. Удалять данные вручную — это вдвойне неблагодарная работа, т.к. механики эффективного удаления данных очень сильно зависят от внутренних особенностей реализации используемого хранилища. Будет отлично, если хранилище поискового индекса предоставляет механизм автоматического удаления старых версий документов. В противном случае нужно будет реализовать механизм асинхронной очистки, а это крайне непростая задача.
К сожалению, не все базы данных имеют средства автоматического схлопывания строк. Из известных мне только ClickHouse имеет подобную функциональность, которая реализуется в виде стратегий CollapsingMergeTree и VersionedCollapsingMergeTree.
Популяционные запросы
Популяционный поиск предполагает наличие витрин данных. В противном случае любой популяционный поиск по “сырым данным” будет медленным, ведь время поиска будет зависеть от размера базы, а это абсолютно неприемлемо.
Строить витрины данных или их подобие вручную, в коде приложения, непозволительно дорого и долго. Нужно рассматривать такие решения, которые будут предлагать максимальную адаптивность к новым или существующим популяционным запросам. Это значит, что используемое хранилище должно предоставлять средства автоматического создания витрин данных — срезов данных, которые будут ускорять выполнение запросов определённого типа. Самый простой способ организации таких “ускорителей” — это материализованные представления, работающие по принципу, который описан выше, в примере автоматического ограничения выборки при поиске по пациенту.
Сначала сервис поиска анализирует запрос и выбирает нужную стратегию поиска. Реализация стратегии знает, какие оптимизации и с помощью каких именно таблиц, можно применить для ускорения входящего запроса.
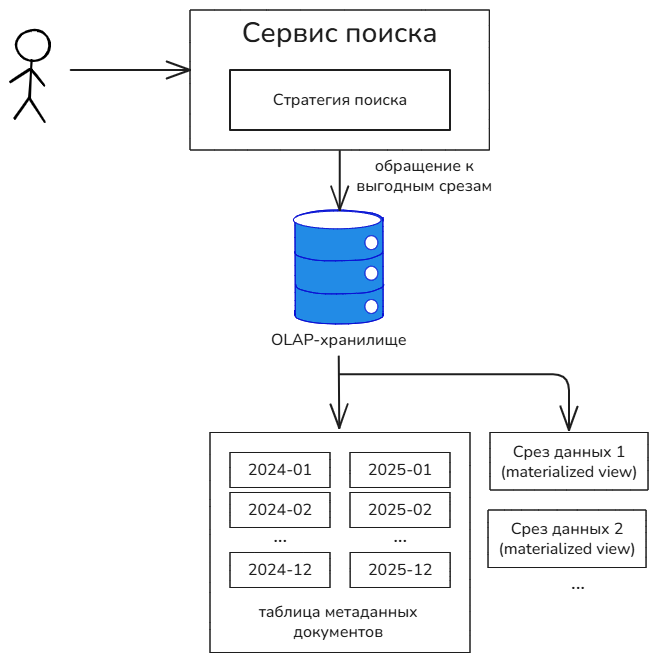
Задержка индексации
Раздельное хранение операционных и аналитических данных решает вопрос быстродействия, но создаёт проблему с запаздыванием данных в поисковом индексе. Сначала метаданные документов будут сохраняться в операционное хранилище, а затем реплицироваться в индексное. В итоге возникает временной зазор, когда документ уже сохранён, но всё ещё недоступен для поиска.
Частично эту задержку можно нивелировать быстрой записью, и в связи с этим можно рассмотреть хранилища, адаптированные для такой нагрузки. Но быстрая запись не всегда достаётся бесплатно. Например, в Cassandra и ClickHouse есть фазы слияния файлов данных (compaction/merge), которые создают всплески нагрузки на I/O и, как следствие, замедляют работу базы.
На следующем рисунке показана ситуация, когда один пользователь изменил документ, а второй не смог его найти или результаты поиска уже устарели.
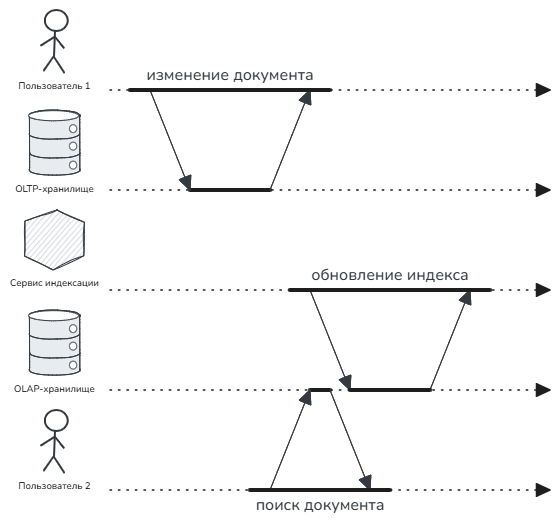
Дополнительно нужно проверить, насколько критично подобное нарушение изоляции для существующих сценариев и интеграций. Вполне возможно, что для некоторых случаев придётся добавлять синхронное ожидание окончания индексации.
Вообще говоря, трудно найти сценарии, когда только что сохранённая медицинская информация должна понадобится моментально, и неточность поиска в рамках небольшого лага индексации окажет непоправимый вред пациенту. Как отмечалось выше, гораздо важней доступность функции поиска, поэтому нужно пойти на оправданный компромисс и принять стратегическое архитектурное решение отказа от необходимости синхронного ожидания окончания индексации. Сценарии, в которых важно реагировать на изменения документов, должны быть переделаны на асинхронный режим работы с помощью подписки на уведомления об изменениях документов (см. выше).
Размер индекса
Можно сделать примерную оценку размера индекса. Для этого нужно составить таблицу из атрибутов документа, их размера и предполагаемой степени сжатия (в зависимости от характера данных).
Например, идентификатор документа имеет тип данных UUID, занимает 16 байт и имеет низкую степень сжатия в районе 1, т.к. UUID имеет высокую вариативность. Дата создания документа имеет тип данных DateTime, занимает 8 байт и имеет высокую степень сжатия в районе 5, т.к. документы упорядочены по дате создания.
Предполагаемую степень сжатия лучше оценить заранее, выполнив ряд тестов, или посмотреть на аналитические рекомендации к той БД или алгоритму, который собираетесь использовать. Например, в документации ClickHouse можно найти статью, в которой даются примерные оценки сжатия данных.
Просуммировав полученные значения, можно получить два показателя: размер сырых данных и предполагаемый размер сжатых данных.
Допустим, анализ показал, что сырые данные одного документа будут занимать 1.5 Kb, а сжатые — 0.5 Kb. Умножив эти показатели на общее количество документов (указанное в условии задачи), можно вычислить предполагаемый размер индекса.
- Сырые данные:
5000000000 * 1.5 Kb = 6.98 Tb - Сжатые данные:
5000000000 * 0.5 Kb = 2.33 Tb
При стабильном приросте 5 млн. документов в день в течение 10 лет в базу будет добавлено еще 18 млрд. документов. Соответственно, легко можно вычислить предполагаемый прирост.
- Сырые данные:
+25.15 Tb(итого32.13 Tb) - Сжатые данные:
+8.38 Tb(итого10.71 Tb)
При факторе репликации x3 получаем следующие значения (учитываются только сжатые данные).
- Текущие потребности:
2.33*3 = 6.98 Tb - Потребности в перспективе 10 лет:
10.71*3 = 32.13 Tb
Масштабирование хранения
База данных непрерывно растёт, а сам рост имеет тенденцию к ускорению (за счёт активной цифровизации). Очевидно, что хранилище данных должно предполагать эффективные механизмы горизонтального масштабирования данных. В идеале оно должно быть простым и адаптивным, с минимальным вмешательством человека.
Вполне возможно, что в будущем понадобится разделение хранилища на горячее и холодное. В холодное хранилище будут перетекать старые данные, т.к. очевидно, что любая медицинская информация со временем утрачивает свою значимость и актуальность. Предложенное выше партиционирование индекса по дате создания документов способствует эффективному решению этой проблемы.
Контроль целостности
Организация поискового индекса в отдельной базе данных предполагает необходимость начального наполнения этой базы, а также её последующей синхронизации с хранилищем оперативных данных. Учитывая, что существующее решение основано на базе SQL-хранилища, начальное наполнение нового поискового индекса можно сделать с помощью CDC-конвейера (Change Data Capture), выполненного с помощью Debezium.
Как показывает практика, в распределённых системах всё может пойти не так, как задумано, поэтому нужно сразу предусмотреть способы оперативной заливки данных в поисковый индекс, его частичной или полной синхронизации с оперативным хранилищем, а также метрики обнаружения рассогласования и потери целостности. Этот контроль нужно производить асинхронно, анализируя результаты поиска.
Требования к хранилищу
Подводя итоги, можно выделить следующие ключевые требования к хранилищу данных для построения поискового индекса:
- специализация на чётком поиске (фильтрации данных);
- специализация на OLAP с колоночным хранением данных;
- возможность партиционирования по времени;
- возможность создания материализованных представлений;
- возможность автоматического удаления старых версий;
- минимальная латентность при сохранении;
- поддержка сжатия данных;
- возможность горизонтального масштабирования;
- открытый исходный код;
- активная поддержка;
- доступная лицензия;
- условная бесплатность.
Дополнительные требования, которые относятся к разряду желательных, но не обязательных:
- удобный язык запросов (желательно SQL-подобный);
- наличие опыта использования и поддержки.
Выбор хранилища
По совокупности обстоятельств идеальным кандидатом для выбора является ClickHouse. Он отвечает всем предъявленным требованиям, включая удобный язык запросов (SQL).
Интересный факт
В рамках конференции HighLoad++ 2025 был доклад “Как мы ускоряли поиск в модели EAV для 13500 атрибутов через ClickHouse” (от МТС/MWS). Решалась схожая задача: у каждого документа большой и вариативный состав атрибутов, по которым производится аналитический поиск. Задача была эффективно решена с использованием ClickHouse и ряда понятных техник, которые также можно взять на вооружение. В рамках секции вопросов-ответов было подмечено, что Apache Druid решает данную задачу не менее эффективно, однако все согласились, что ClickHouse более известная и развитая технология.
План реализации
Примерный план реализации нового решения таков.
- Согласовать базовый вариант схемы данных поискового индекса.
- Сделать первоначальное наполнение индекса с помощью CDC-конвейера. При копировании данных важно следить за состоянием БД и инфраструктуры. Возможно, это даст подсказки относительно эффективности схемы данных; добавит понимание относительно задержек при записи.
- Провести нагрузочное тестирование, используя типовые поисковые запросы. До автоматического тестирования следует провести ручное тестирование выполнения типовых запросов. Как правило, этого вполне достаточно, чтобы найти основные огрехи схемы данных. Когда ручная проверка перестанет давать результаты, можно переходить к настоящему нагрузочному тестированию.
- Итеративно повторять предыдущие шаги, пока не будут достигнуты желаемые показатели по производительности, нагрузке на CPU, I/O.
- Последним шагом добавить поддержку нового поиска в код сервиса. При внедрении нового поиска желательно использовать канареечное развертывание с возможностью отката на предыдущий вариант поиска.
Послесловие
Посмею напомнить, что это один из возможных вариантов решения задачи. Как и всегда, подобные решения должны проходить многократные стадии тестирования и апробации. Полное решение достаточно сложное, поэтому важно спланировать свою работу таким образом, чтобы как можно раньше убедиться в его перспективности.
Понравилась статья?
Посмею напомнить, что у меня есть Telegram-канал Архитектоника в ИТ, где я публикую материал на похожие темы примерно раз в неделю. Подписчики меня мотивируют, но ещё больше мотивируют живые дискуссии, ведь именно в них рождается истина. Поэтому подписывайтесь на канал и будем оставаться на связи! ;-)
Статьи из той же категории: