Решардирование данных через промежуточный топик
Есть интересный алгоритм, который позволяет не только увеличить пропускную способность потока обработки данных, но и значительно сократить нагрузку на сеть и брокер сообщений.
Контекст
Существует множество серверов для обслуживания большого потока пользовательских запросов. Например, для обработки поисковых запросов, сбора клиентской телеметрии, создания документов в крупной медицинской системе и т.д. Помимо основной логики обработки формируется лог запросов для их последующего (асинхронного) анализа. Лог запросов формируется в виде топика Log-based-брокера, например, в Apache Kafka, который обслуживает набор специализированных серверов-обработчиков. Такая обработка может формировать, например, топ поисковых запросов или список интересов пользователя.
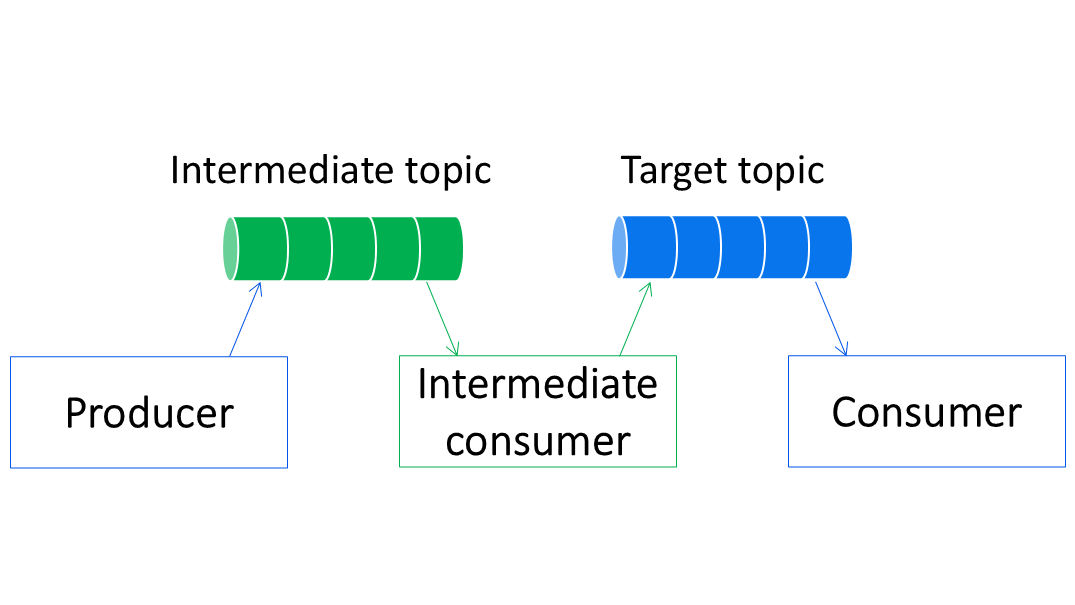
Таким образом, одно подмножество серверов — продюсеры; второе — консюмеры. Чаще всего в таких случаях топики партиционируют так, чтобы консюмеру было удобно получать и обрабатывать данные. Такое удобство может диктоваться необходимостью пакетной обработки, соблюдения порядка событий, локальностью данных и т.п.
Проблемы
- Продюсеры берут на себя обязательства по обеспечению удобства обработки данных топика, в который они пишут.
- Возможно снижение эффективности записи в топик, если топик имеет множество партиций, а ключ партиционирования варьируется в большом диапазоне. Например, партиционирование по идентификатору пользователя или документа. Из-за этого продюсер будет накапливать пачки сообщений меньших размеров для записи в конкретную партицию. При большом разбросе ключей запись в каждую партицию может идти без пакетирования, что увеличивает транспортные расходы и нагрузку на брокер.
- Возможна слишком большая нагрузка на брокер и сеть, если количество продюсеров и партиций велико. Каждый продюсер создаёт TCP-соединение с брокером, отвечающим за партицию, в которую производится запись. При большом количестве партиций для
Pпродюсеров иBброкеров будет созданоP*Bсоединений. В результате при масштабировании системы могут существенно возрасти транспортные расходы, нагрузка на брокер и сеть.
Решение
Продюсер должен писать не в целевой топик, а в промежуточный, который будет удобен для записи. Промежуточный топик обслуживается ограниченным количеством специализированных консюмеров, задача которых — переложить данные из промежуточного топика (удобного для записи) в целевой (удобный для обработки). Ключ партиционирования промежуточного топика должен варьироваться в небольшом диапазоне. Например, партиционирование по идентификатору продюсера.
Этот подход называется решардированием данных на основе промежуточного агрегирующего слоя.
Плюсы
- Продюсер пишет так, как ему удобно.
- Используется пакетная запись. Вариативность ключей партиционирования промежуточного топика ограничена сильней, чем целевого. Следовательно, при интенсивной записи гораздо больше шансов, что продюсер будет отправлять в партиции промежуточного топика более объемные пакеты.
- Нагрузка на брокер и сеть снижается. Из-за небольшого количества уникальных ключей партиционирования промежуточного топика, количество его партиций меньше количества партиций целевого топика. Следовательно, продюсеры будут подключаться лишь к ограниченному количеству брокеров, а не ко всем, как раньше. Одновременно с этим, количество обработчиков промежуточного топика также меньше числа продюсеров, что также снижает количество соединений к брокерам.
Например, для обработки пользовательских запросов необходимо поднять
P=1000серверов. Пусть всего имеетсяB=10брокеров; а лог запросов партиционирован по идентификатору пользователя и имеет1000партиций. Скорей всего, в такой системе будет околоP*B=1000*10=10000TCP-соединений между продюсерами и брокерами (т.к. каждый продюсер будет соединён с каждым брокером).Если добавить промежуточный топик с партиционированием по продюсеру, то уникальных ключей будет
P=1000. Допустим, мы решили, что для такого топика достаточно сделать10партиций и, соответственно, доС=10промежуточных консюмеров. В такой системе количество TCP-соединений с брокерами будет не болееP*1+С*B=1000*1+10*10=1010, что на порядок меньше предыдущего варианта.
Минусы
- Усложнение архитектуры. Увеличивается кодовая база, усложняется алгоритм обработки, деплой и обслуживание приложения.
- Отсутствие гарантий ACID. Соответственно, всё те же проблемы с гарантиями доставки, дублированием, идемпотентностью и т.п. (В YDB Topics эта проблема решена.)
- Увеличение времени доставки данных в целевой топик.
- Увеличение размера хранимых данных.
Понравилась статья?
Посмею напомнить, что у меня есть Telegram-канал Архитектоника в ИТ, где я публикую материал на похожие темы примерно раз в неделю. Подписчики меня мотивируют, но ещё больше мотивируют живые дискуссии, ведь именно в них рождается истина. Поэтому подписывайтесь на канал и будем оставаться на связи! ;-)
Статьи из той же категории: