Lamport Timestamp: генерация целочисленного идентификатора в распределённой БД без ACID-транзакций
В далёком 1978 году Leslie Lamport — американский учёный в области информатики и распределённых систем — предложил простой и эффективный способ определения порядка событий в распределённой системе. Позже этот алгоритм так и назвали: Lamport Timestamp. Давайте разберёмся, как данный алгоритм можно использовать на практике. В качестве примера рассмотрим задачу, более приземлённую к прикладной разработке.
Контекст
Существует таблица, где в качестве первичного ключа используется целочисленный идентификатор. Это типичная и привычная ситуация для монолитных баз данных (PostgreSQL, MySQL, MariaDB, Oracle, MS SQL и т.п.). Подобные базы имеют встроенный механизм автоматической генерации целочисленных идентификаторов, который можно подключить при создании таблицы. Те, кто впервые сталкивается с распределёнными базами, с удивлением обнаруживают, что многие из них не имеют подобной функциональности, также как и ACID-транзакций, а в качестве первичного ключа предлагают использовать UUID. Понятно, что такие ограничения имеют серьезные основания, связанные с производительностью и сложностью согласования изменений между репликами базы данных.
Однако предположим, что по каким-то причинам нет возможности использовать UUID в качестве первичного ключа. Например, производится миграция из существующей монолитной базы в распределенную.
Один из вариантов решения — внешний генератор последовательности. Например, всё та же монолитная база (см. SEQUENCE); какой-либо координатор (ZooKeeper, etcd и т.п.); распределённые кэши (Redis, Hazelcast, Ignite и т.п.). Обычно используют то, что уже есть в окружении. Основной недостаток — счетчик может быть сброшен независимо от базы, в которой он используется. Например, в следствии восстановления базы из бэкапа.
Проблема
Несколько экземпляров приложения (далее для краткости — клиентов) обращаются к распределённой базе данных с целью добавления новых записей, присваивая каждой уникальный целочисленный идентификатор. При этом база данных не поддерживает ACID-транзакции. В этих условиях нужно решить задачу генерации уникальной согласованной целочисленной последовательности в распределённой среде. Любые коллизии недопустимы.
Решение
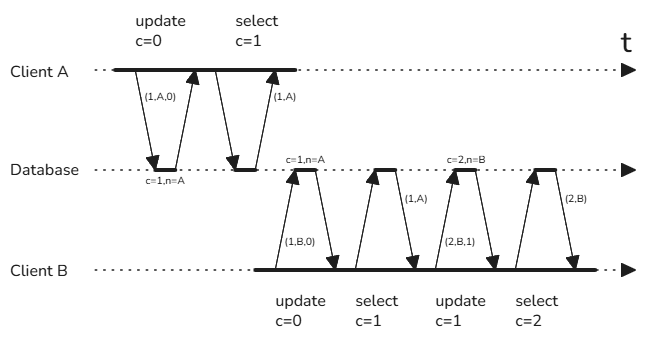
Иллюстрация шагов алгоритма приведена в заголовке статьи. Клиенты
AиBпытаются последовательно увеличить на1значение счетчикаcв базе, изначально полагая, что значение этого счетчика равно0. При обращении к базе каждый из клиентов отправляет свой уникальный идентификаторn.
В целевой базе данных создать таблицу counters с тремя колонками:
-
name— имя последовательности; -
node— уникальный идентификатор клиента; -
value— последнее использованное значение последовательности.
Таблица хранит именованные пары (node,value), которые и являются Lamport Timestamps.
В качестве примера будем использовать Apache Cassandra:
CREATE TABLE counters (
name text PRIMARY KEY,
node uuid,
value bigint
)
Шаг 1: Увеличение счётчика
Каждый клиент знает имя последовательности, имеет уникальный идентификатор и хранит максимальное значение последовательности, о котором он знает. Для генерации нового значения выполняется UPDATE-запрос вида:
UPDATE counters SET
node = <client UUID>,
value = <new value> -- <old value> + 1
WHERE name = <seq name>
IF value = <old value>
Запись обновится только в том случае, если текущее значение совпадает со значением, которое было известно клиенту.
Шаг 2: Проверка счётчика
Для проверки успешности обновления счётчика выполняется SELECT-запрос:
SELECT node, value
FROM counters
WHERE name = <seq name>
Клиент запоминает полученное актуальное значение последовательности и сравнивает свой уникальный идентификатор с полученным. Если идентификаторы идентичны, значит, предыдущий запрос выполнен успешно и можно использовать полученное значение. Если идентификаторы отличаются, значит, нужно повторить все действия с первого шага.
Для минимизации обращений к базе данных и количества возможных конфликтов крайне рекомендуется, чтобы клиент резервировал диапазон значений.
Реализация подхода умещается в один небольшой файл. Пример написан на Java для Apache Cassandra, но его легко можно портировать на любой другой язык и базу данных.
Плюсы
Наипростейшая реализация. База данных полностью самодостаточна и независима от внешних инструментов.
Минусы
При запросе диапазонов значений возможны некоторые пропуски. Например, два клиента запросили по 1000 значений. Один клиент с 1 по 1000, другой с 1001 по 2000. Оба клиента создают записи в базе, но один из них был остановлен или перезапущен до того, как использовал все запрошенные значения. Неиспользованные значения будут потеряны навсегда, т.к. последовательность только увеличивается.
Сталкивались ли вы с подобной проблемой на практике и как её решали? Сначала я начал использовать внешний генератор на основе PostgreSQL Sequences, но потом вспомнил про Lamport Timestamps и сейчас очень доволен тем, что получилось!
Понравилась статья?
Посмею напомнить, что у меня есть Telegram-канал Архитектоника в ИТ, где я публикую материал на похожие темы примерно раз в неделю. Подписчики меня мотивируют, но ещё больше мотивируют живые дискуссии, ведь именно в них рождается истина. Поэтому подписывайтесь на канал и будем оставаться на связи! ;-)
Статьи из той же категории: